Mingze Wang
 |
Mingze Wang (王铭泽) DeepSeek AI, Backbone group Ph.D. graduate at Peking University Email: mingzewang.math [at] gmail.com / mingzewang [at] deepseek.com |
About me
I am a Ph.D graduate at Computational Mathematics, School of Mathematical Sciences, Peking University (2026). I am very fortunate to be advised by Prof. Weinan E. Prior to that, I received my B.S. degree in Pure and Applied Mathematics (ranking 1/111 for the first three years during my undergraduate study) from School of Mathematical Sciences, Zhejiang University, Hangzhou, China in 2021.
I am currently a researcher at DeepSeek AI, Backbone group.
Research Interests
I am broadly interested in theory, algorithm and application of machine learning. I am also interested in non-convex and convex optimization. Recently, I am dedicated to developing theoretically grounded and elegant algorithms to address challenges in foundation models or quantitative trading.
My recent research topics are
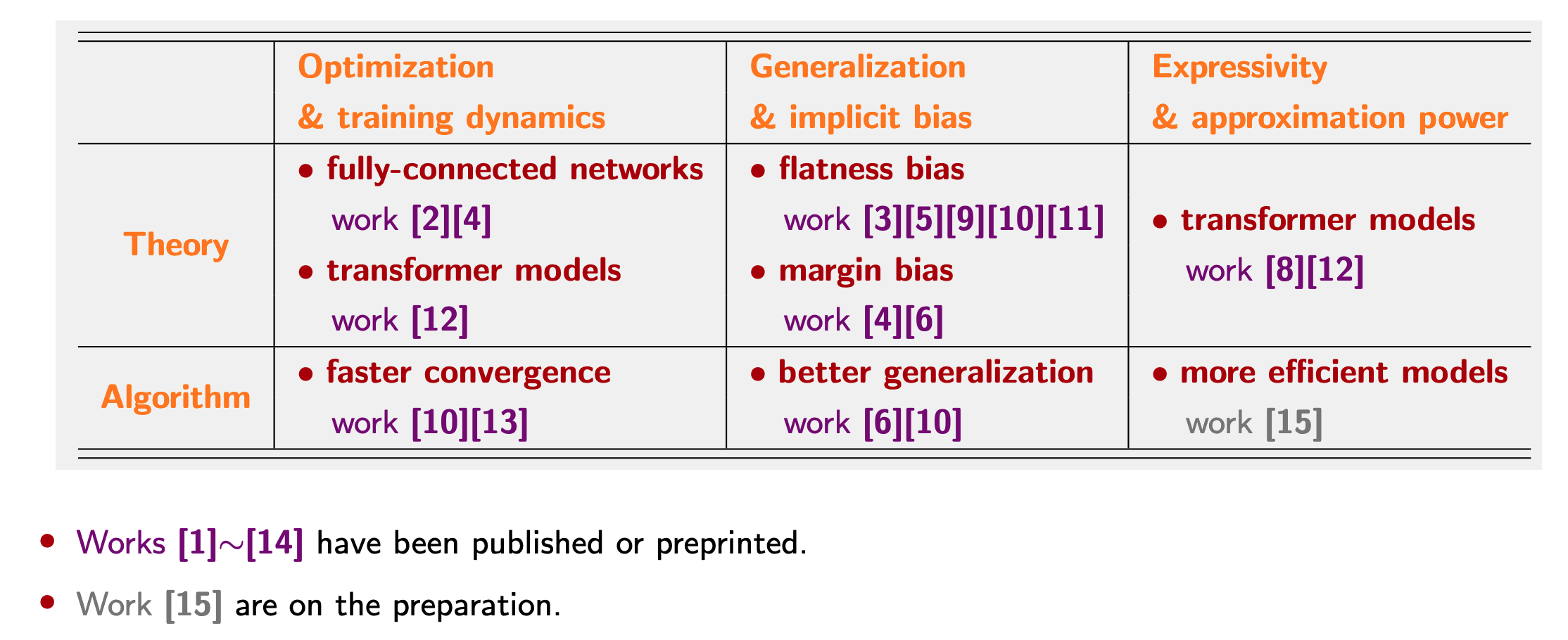
Deep Learning Theory:
Expressivity and approximation power. Understanding the expressive power and working mechanisms of Transformers and MoEs.
Optimization and training dynamics. Analyzing multi-phase optimization dynamics and rich nonlinear behaviors of FFNs and Transformers.
Generalization and implicit bias. Investigating the selection mechanism of generalizable minima in training over-parameterized neural networks.
Deep Learning Algorithm:
Faster convergence. Accelerating slow dynamics along flat directions while controlling fast fluctuations along sharp directions in LLM pre-training.
More expressive model. Improving neural network expressivity with negligible overhead, while accounting for interactions with optimization.
Better generalization. Enhancing the flatness bias or large-margin bias of over-parameterized neural networks and optimziers.
Transformer and Large Language Model: theory and algorithm, with a particular focus on LLM pre-training.
Non-convex and Convex Optimization: theory and algorithm.
Specifically, my research on deep learning theory and algorithm can be summarized as:
 |
My current research is supported the Young Scientists (Ph.D) Fund of the National Natural Science Foundation of China. (Analyzing and Improving the Adam Optimizer for Foundation Model Training)
Recent Publications and Preprints
* indicates equal contribution, † means project lead.
[22] Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
Mingze Wang†, Shuchen Zhu, Yuxin Fang, Binghui Li, Kai Shen, Shu Zhong.
under review, 1-36. May 2026.[21] More Expressive Feedforward Layers: Part I. Token-Adaptive Mixing of Activations
Mingze Wang†, Jinbo Wang, Yikuan Xia, Kai Shen, Shu Zhong.
under review, 1-31. May 2026.[20] Accelerating LLM Pre-training through Flat-Direction Dynamics Enhancement
Shuchen Zhu, Rizhen Hu, Mingze Wang†, Mou Sun, Xue Wang, Kun Yuan, Zaiwen Wen.
under review, arXiv preprint, 1-43. Feb 2026.[19] Low-probability Tokens Sustain Exploration in Reinforcement Learning with Verifiable Reward
Guanhua Huang*, Tingqiang Xu*, Mingze Wang, Qi Yi, Xue Gong, Siheng Li, Ruibin Xiong, Kejiao Li, Yuhao Jiang, Bo Zhou.
2026 Annual Meeting of the Association for Computational Linguistics (ACL 2026, Findings) 1-21.[18] Fast Catch-Up, Late Switching: Optimal Batch Size Scheduling via Functional Scaling Laws
Jinbo Wang*, Binghui Li*, Zhanpeng Zhou, Mingze Wang, Yuxuan Sun, Jiaqi Zhang, Xunliang Cai, Lei Wu.
2026 International Conference on Learning Representations (ICLR 2026).[17] GradPower: Powering Gradients for Faster Language Model Pre-Training
Jinbo Wang*, Mingze Wang*†, Jiaqi Zhang, Wei Wang, Peng Pei, Xunliang Cai, Weinan E, Lei Wu.
2026 International Conference on Machine Learning (ICML 2026), 1-22.[16] On the Expressive Power of Mixture-of-Experts for Structured Complex Tasks
Mingze Wang†, Weinan E.
2025 Conference on Neural Information Processing Systems (NeurIPS 2025) (Spotlight, top 3.5%), 1-18.[15] On the Learning Dynamics of Two-layer Linear Networks with Label Noise SGD
Tongcheng Zhang, Zhanpeng Zhou, Mingze Wang, Andi Han, Wei Huang, Taiji Suzuki, Junchi Yan.
2026 AAAI Conference on Artificial Intelligence (AAAI 2026) (Oral).[14] A Single Global Merging Suffices: Recovering Centralized Learning Performance in Decentralized Learning
Tongtian Zhu, Tianyu Zhang, Mingze Wang, Zhanpeng Zhou, Can Wang.
2026 International Conference on Learning Representations (ICLR 2026) (Oral, top 1.2%), 1-23.[13] The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
Jinbo Wang*, Mingze Wang*†, Zhanpeng Zhou*, Junchi Yan, Weinan E, Lei Wu.
2025 International Conference on Machine Learning (ICML 2025), 1-23.[12] How Transformers Get Rich: Approximation and Dynamics Analysis
Mingze Wang†, Ruoxi Yu, Weinan E, Lei Wu.
ICML 2025 Workshop on High-dimensional Learning Dynamics (ICML 2025 - HiLD), 1-47.[11] Sharpness-Aware Minimization Efficiently Selects Flatter Minima Late in Training
Zhanpeng Zhou*, Mingze Wang*, Yuchen Mao, Bingrui Li, Junchi Yan.
2025 International Conference on Learning Representations (ICLR 2025) (Spotlight, top 5.1%), 1-31.[10] Improving Generalization and Convergence by Enhancing Implicit Regularization
Mingze Wang†, Jinbo Wang, Haotian He, Zilin Wang, Guanhua Huang, Feiyu Xiong, Zhiyu Li, Weinan E, Lei Wu
2024 Conference on Neural Information Processing Systems (NeurIPS 2024), 1-44.[9] Loss Symmetry and Noise Equilibrium of Stochastic Gradient Descent
Liu Ziyin, Mingze Wang, Hongchao Li, Lei Wu
2024 Conference on Neural Information Processing Systems (NeurIPS 2024), 1-26.[8] Understanding the Expressive Power and Mechanisms of Transformer for Sequence Modeling
Mingze Wang, Weinan E
2024 Conference on Neural Information Processing Systems (NeurIPS 2024), 1-76.[7] Are AI-Generated Text Detectors Robust to Adversarial Perturbations?
Guanhua Huang, Yuchen Zhang, Zhe Li, Yongjian You, Mingze Wang, Zhouwang Yang
2024 Annual Meeting of the Association for Computational Linguistics (ACL 2024), 1-20.[6] Achieving Margin Maximization Exponentially Fast via Progressive Norm Rescaling
Mingze Wang†, Zeping Min, Lei Wu
2024 International Conference on Machine Learning (ICML 2024), 1-38.[5] A Theoretical Analysis of Noise Geometry in Stochastic Gradient Descent
Mingze Wang, Lei Wu
NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning (NeurIPS 2023 - M3L), 1-30.[4] Understanding Multi-phase Optimization Dynamics and Rich Nonlinear Behaviors of ReLU Networks
Mingze Wang†, Chao Ma
2023 Conference on Neural Information Processing Systems (NeurIPS 2023) (Spotlight, top 3.5%), 1-94.[3] The alignment property of SGD noise and how it helps select flat minima: A stability analysis
Lei Wu, Mingze Wang, Weijie J. Su
2022 Conference on Neural Information Processing Systems (NeurIPS 2022), 1-25.[2] Early Stage Convergence and Global Convergence of Training Mildly Parameterized Neural Networks
Mingze Wang†, Chao Ma
2022 Conference on Neural Information Processing Systems (NeurIPS 2022), 1-73.[1] Generalization Error Bounds for Deep Neural Networks Trained by SGD
Mingze Wang†, Chao Ma
arXiv preprint, 1-32, June 2022.
Selected Awards and Honours
ByteDance Scholarship (awarded to 20 students in China and Singapore); my advisor received the best mentor award, 2025.
Young Scientists (Ph.D) Fund of the National Natural Science Foundation of China (¥300,000), 2024.
China National Scholarship (top 0.2% in the nation), The Ministry of Education, 2024.
Principal Scholarship, Peking University, 2024; 2025.
BICMR Mathematical Award for Graduate Students (top 1%), Peking University, 2023.
PKU Academic Innovation Award (top 1%), Peking University, 2022.
Outstanding Graduate of Zhejiang Province (top 5%), Zhejiang Province, 2021.
First Class Scholarship of ZJU (top 3%), Zhejiang University, 2019; 2020.
China National Scholarship (top 0.2% in the nation), The Ministry of Education, 2019.
Selected Experience
Foundation Models
DeepSeek AI, Backbone group, Beijing, China
Researcher (2026.7-now).
Frontier research of model architecture and optimization for foundation models.
ByteDance Seed, Edge group, Beijing, China.
Research Intern (Topseed intern) (2026.2-2026.6).
Frontier research of foundation models.
Tencent Hunyuan, Post-training group, Beijing, China.
Research Intern (Qingyun intern) (2025.6-2025.7).
Work on designing verifiable rewards of reinforcement learning for LLM post-training.
Meituan, LLM pre-training group, Beijing, China.
Research Intern (2025.1-2025.5).
Work on designing stable and faster optimization algorithms for LLM pre-training.
Institute for Advanced Algorithms Research, LLM group, Shanghai, China.
Research Intern (2023.12-2024.8).
Work on designing faster optimization algorithms for LLM pre-training.
Quantitative Trading
Definite Capital Management, Beijing, China.
Research Intern (2025.10-2025.12).
Work on designing better deep learning models and training strategies in quantitative trading.
Wizard Quant, Beijing, China.
Research Intern (2025.8.1).
Service and Teaching
Reviewer for
Conference: Conference on Neural Information Processing Systems (NeurIPS) (NeurIPS 2025 Top Reviewer); International Conference on Machine Learning (ICML); International Conference on Learning Representations (ICLR); Artificial Intelligence and Statistics (AISTATS).
Journal: Journal of Machine Learning Research (JMLR); Transactions on Pattern Analysis and Machine Intelligence (TPAMI); Pattern Recognition (PR); Transactions on Machine Learning Research (TMLR); Journal of Machine Learning (JML).
Teaching assistant
Deep Learning Theory, taught by Prof. Zhiyuan Li (TTIC), Peking University (Summer School 2023).
Calculus, Peking University (from Fall 2021 to Fall 2024).
Recent News
[2026.04] One paper accepted to ICML 2026. One paper accepted to ACL 2026.
[2026.01] Two paper accepted to ICLR 2026. One of them was selected for an Oral (top 1.2%).
[2025.11] I won the 2025 ByteDance Scholarship (awarded to 20 students in China and Singapore).
[2025.09] One paper accepted to NeurIPS 2025 as a Spotlight (top 3.5%).
[2025.05] One paper accepted to ICML 2025.
[2025.01] One paper accepted to ICLR 2025 as a Spotlight (top 5.1%).
[2024.12] I received support from the Young Scientists (Ph.D) Fund of the National Natural Science Foundation of China.
[2024.09] I won the 2024 China National Scholarship (top 0.2% in the nation).
[2024.09] Three papers accepted to NeurIPS 2024.
[2024.05] One paper accepted to ICML 2024. One paper accepted to ACL 2024.
[2023.11] I won the 2023 BICMR Mathematical Award for Graduate Students (top 1%).
[2023.09] One paper accepted to NeurIPS 2023 as a Spotlight (top 3.5%).
[2022.11] I have passed the Ph.D. qualifying exam.
[2022.10] I won the 2022 PKU Academic Innovation Award (top 1%).
[2022.09] Two papers accepted to NeurIPS 2022.
