王铭泽
 |
王铭泽 (Mingze Wang) DeepSeek AI, Backbone 组 北京大学 博士毕业生 电子邮箱: mingzewang.math [at] gmail.com / mingzewang [at] deepseek.com |
关于我
我是北京大学数学科学学院计算数学专业的博士毕业生 (2026)。 我非常荣幸能得到鄂维南院士的指导。 在此之前,我于 2021 年在浙江大学数学科学学院获得了数学与应用数学学士学位 (本科前三年排名为 1/111)。
我是 DeepSeek AI Backbone 组的研究员。
研究兴趣
我对机器学习的理论、算法和应用有着广泛的兴趣。我对非凸和凸优化也很感兴趣。最近,我致力于设计有理论保证且优雅的算法,来解决大模型或量化交易场景中的挑战。
我最近的研究课题是
深度学习理论:
表达能力与逼近能力. 理解 Transformer 和混合专家模型 (MoE) 的表达能力与工作机制。
优化与训练动力学. 分析前馈网络 (FFN) 和 Transformer 的多阶段优化动力学及其丰富的非线性行为。
泛化与隐式偏置. 探究过参数化神经网络与优化器中可泛化极小值的选择机制。
深度学习算法:
更快的收敛. 在 LLM 预训练中,加速沿平坦方向的慢动力学,同时控制沿陡峭方向的快速震动。
更具表达力的模型. 以极低的额外开销提升神经网络的表达力,并兼顾其与优化过程之间的相互作用。
更好的泛化. 增强过参数化神经网络与优化器的平坦性偏置或大间隔偏置。
Transformer和大型语言模型:理论与算法,特别在大模型预训练中。
非凸和凸优化:理论与算法。
具体来说,我在深度学习理论和算法方面的研究可以被概括为:
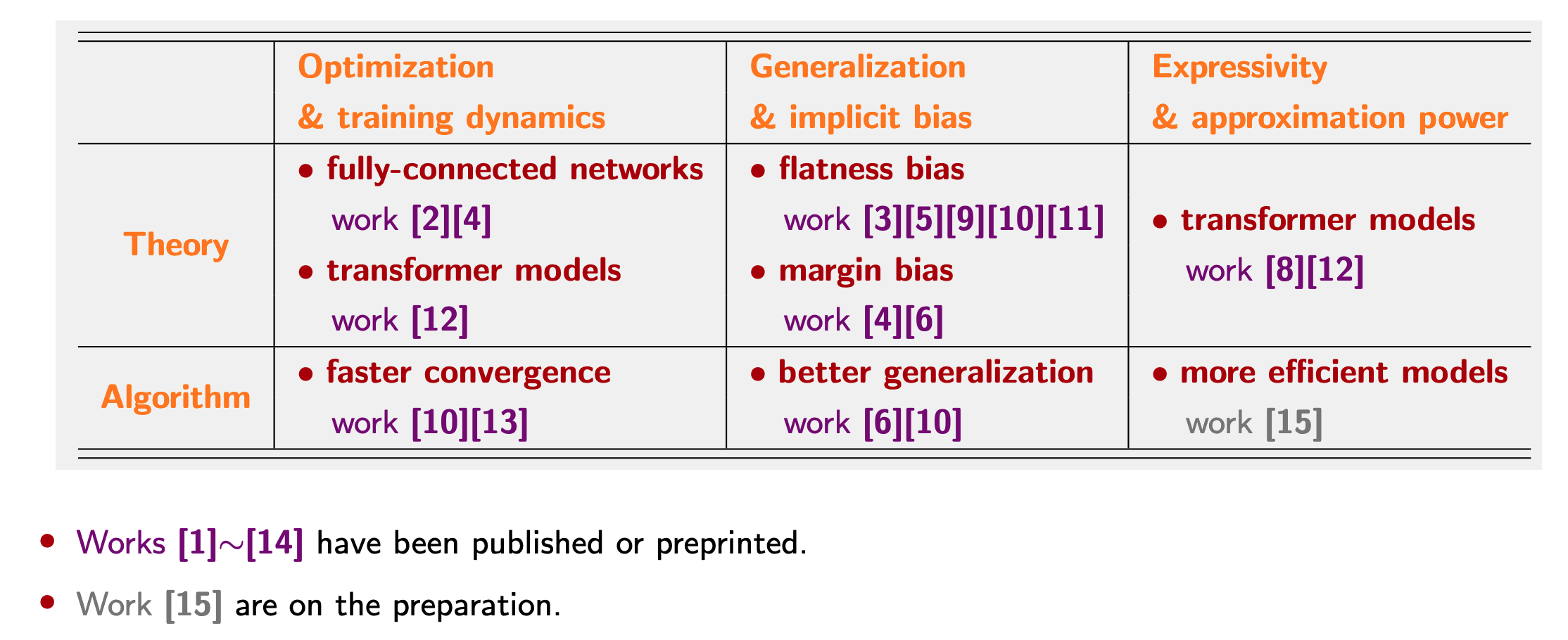 |
我目前的研究获得了 国家自然科学基金青年学生基础研究项目(博士研究生)的资助. (课题:大模型训练中Adam优化算法的分析和改进)
发表论文
* 表示平等贡献,† 表示主导项目.
[22] Negligible in Size, Significant in Effect: On Scale Vectors in Large Language Models
Mingze Wang† (王铭泽), Shuchen Zhu (朱书辰), Yuxin Fang (方羽新), Binghui Li (李柄辉), Kai Shen (沈锴), Shu Zhong (钟书).
under review, 1-36. May 2026.[21] More Expressive Feedforward Layers: Part I. Token-Adaptive Mixing of Activations
Mingze Wang† (王铭泽), Jinbo Wang (王锦波), Yikuan Xia (夏逸宽), Kai Shen (沈锴), Shu Zhong (钟书).
under review, 1-31. May 2026.[20] Accelerating LLM Pre-training through Flat-Direction Dynamics Enhancement
Shuchen Zhu (朱书辰), Rizhen Hu, Mingze Wang† (王铭泽), Mou Sun, Xue Wang, Kun Yuan (袁坤), Zaiwen Wen (文再文).
under review, arXiv preprint, 1-43. Feb 2026.[19] Low-probability Tokens Sustain Exploration in Reinforcement Learning with Verifiable Reward
Guanhua Huang* (黄冠华), Tingqiang Xu* (许庭强), Mingze Wang (王铭泽), Qi Yi, Xue Gong, Siheng Li, Ruibin Xiong, Kejiao Li, Yuhao Jiang, Bo Zhou (周波).
2026 Annual Meeting of the Association for Computational Linguistics (ACL 2026, Findings) 1-21.[18] Fast Catch-Up, Late Switching: Optimal Batch Size Scheduling via Functional Scaling Laws
Jinbo Wang* (王锦波), Binghui Li* (李柄辉), Zhanpeng Zhou (周展鹏), Mingze Wang (王铭泽), Yuxuan Sun, Jiaqi Zhang (张家绮), Xunliang Cai (蔡勋梁), Lei Wu (吴磊).
2026 International Conference on Learning Representations (ICLR 2026).[17] GradPower: Powering Gradients for Faster Language Model Pre-Training
Jinbo Wang* (王锦波), Mingze Wang*† (王铭泽), Jiaqi Zhang (张家绮), Wei Wang (王玮), Peng Pei (裴鹏), Xunliang Cai (蔡勋梁), Weinan E (鄂维南), Lei Wu (吴磊).
2026 International Conference on Machine Learning (ICML 2026), 1-22.[16] On the Expressive Power of Mixture-of-Experts for Structured Complex Tasks
Mingze Wang† (王铭泽), Weinan E (鄂维南).
2025 Conference on Neural Information Processing Systems (NeurIPS 2025) (Spotlight, 前 3.5%), 1-18.[15] On the Learning Dynamics of Two-layer ReLU Networks with Label Noise SGD
Tongcheng Zhang (张桐铖), Zhanpeng Zhou (周展鹏), Mingze Wang (王铭泽), Andi Han, Wei Huang (黄伟), Taiji Suzuki, Junchi Yan (严骏驰).
2026 AAAI Conference on Artificial Intelligence (AAAI 2026) (Oral).[14] A Single Global Merging Suffices: Recovering Centralized Learning Performance in Decentralized Learning
Tongtian Zhu (朱同天), Tianyu Zhang (张天宇), Mingze Wang (王铭泽), Zhanpeng Zhou (周展鹏), Can Wang.
2026 International Conference on Learning Representations (ICLR 2026) (Oral, 前 1.2%), 1-23.[13] The Sharpness Disparity Principle in Transformers for Accelerating Language Model Pre-Training
Jinbo Wang* (王锦波), Mingze Wang*† (王铭泽), Zhanpeng Zhou* (周展鹏), Junchi Yan (严骏驰), Weinan E (鄂维南), Lei Wu (吴磊).
2025 International Conference on Machine Learning (ICML 2025), 1-23.[12] How Transformers Get Rich: Approximation and Dynamics Analysis
Mingze Wang†, Ruoxi Yu, Weinan E (鄂维南), Lei Wu (吴磊).
ICML 2025 Workshop on High-dimensional Learning Dynamics (ICML 2025 - HiLD), 1-47.[11] Sharpness-Aware Minimization Efficiently Selects Flatter Minima Late in Training
Zhanpeng Zhou (周展鹏)*, Mingze Wang* (王铭泽), Yuchen Mao, Bingrui Li (李炳睿), Junchi Yan (严骏驰).
2025 International Conference on Learning Representations (ICLR 2025) (Spotlight, 前 5.1%), 1-31.[10] Improving Generalization and Convergence by Enhancing Implicit Regularization
Mingze Wang† (王铭泽), Jinbo Wang (王锦波), Haotian He (何浩田), Zilin Wang (王梓麟), Guanhua Huang (黄冠华), Feiyu Xiong (熊飞宇), Zhiyu Li (李志宇), Weinan E (鄂维南), Lei Wu (吴磊)
2024 Conference on Neural Information Processing Systems (NeurIPS 2024), 1-44.[9] Loss Symmetry and Noise Equilibrium of Stochastic Gradient Descent
Liu Ziyin (刘子寅), Mingze Wang (王铭泽), Hongchao Li, Lei Wu (吴磊)
2024 Conference on Neural Information Processing Systems (NeurIPS 2024), 1-26.[8] Understanding the Expressive Power and Mechanisms of Transformer for Sequence Modeling
Mingze Wang (王铭泽), Weinan E (鄂维南)
2024 Conference on Neural Information Processing Systems (NeurIPS 2024), 1-76.[7] Are AI-Generated Text Detectors Robust to Adversarial Perturbations?
Guanhua Huang (黄冠华), Yuchen Zhang, Zhe Li, Yongjian You, Mingze Wang (王铭泽), Zhouwang Yang (杨周旺)
2024 Annual Meeting of the Association for Computational Linguistics (ACL 2024), 1-20.[6] Achieving Margin Maximization Exponentially Fast via Progressive Norm Rescaling
Mingze Wang† (王铭泽), Zeping Min (闵泽平), Lei Wu (吴磊)
2024 International Conference on Machine Learning (ICML 2024), 1-38.[5] A Theoretical Analysis of Noise Geometry in Stochastic Gradient Descent
Mingze Wang (王铭泽), Lei Wu (吴磊)
NeurIPS 2023 Workshop on Mathematics of Modern Machine Learning (NeurIPS 2023 - M3L), 1-30.[4] Understanding Multi-phase Optimization Dynamics and Rich Nonlinear Behaviors of ReLU Networks
Mingze Wang† (王铭泽), Chao Ma (马超)
2023 Conference on Neural Information Processing Systems (NeurIPS 2023) (Spotlight, 前 3.5%), 1-94.[3] The alignment property of SGD noise and how it helps select flat minima: A stability analysis
Lei Wu (吴磊), Mingze Wang (王铭泽), Weijie J. Su (苏炜杰)
2022 Conference on Neural Information Processing Systems (NeurIPS 2022), 1-25.[2] Early Stage Convergence and Global Convergence of Training Mildly Parameterized Neural Networks
Mingze Wang† (王铭泽), Chao Ma (马超)
2022 Conference on Neural Information Processing Systems (NeurIPS 2022), 1-73.[1] Generalization Error Bounds for Deep Neural Networks Trained by SGD
Mingze Wang† (王铭泽), Chao Ma (马超)
arXiv preprint, 1-32, June 2022.
部分奖项及荣誉
字节跳动奖学金 (颁发给中国和新加坡共20名学生); 我的导师被授予最佳导师奖, 2025.
国家自然科学基金青年学生基础研究项目(博士研究生) (30万元), 2024.
国家奖学金 (博士) (全国前 0.2%), 教育部, 2024.
校长奖学金, 北京大学, 2024; 2025.
北大数学研究生奖 (前 1%), 北京大学, 2023.
北京大学学术创新奖 (前 1%), 北京大学, 2022.
浙江省优秀毕业生 (前 5%), 浙江省, 2021.
浙江大学一等奖学金 (前 3%), 浙江大学, 2019; 2020.
国家奖学金 (本科) (全国前 0.2%), 教育部, 2019.
部分经历
大模型
DeepSeek AI, Backbone 组, 北京, 中国
研究员 (2026.7-now).
大模型的模型结构和优化的前沿探索.
字节跳动 Seed, Edge 组, 北京, 中国.
Algorithm Intern (Topseed 计划) (2026.2-2026.6).
大模型前沿探索。
腾讯混元, Post-training 组, 北京, 中国.
研究实习生 (青云计划) (2025.6-2025.7).
设计 LLM 训练后强化学习的可验证奖励。
美团, LLM pre-training 组, 北京, 中国.
研究实习生 (2025.1-2025.5).
设计稳定的、收敛性能更好的 LLM 预训练优化算法。
上海算法创新研究院, LLM group, 上海, 中国.
研究实习生 (2023.12-2024.8).
设计收敛性能更好的 LLM 预训练优化算法。
量化交易
正定私募, 北京, 中国.
研究实习生 (2025.10-2025.12).
设计量化交易中更好的深度学习模型和训练策略。
宽德投资, 北京, 中国.
研究实习生 (2025.8.1).
设计量化交易中更好的机器学习模型。
服务和教学
审稿人
会议: Conference on Neural Information Processing Systems (NeurIPS) (NeurIPS 2025 Top Reviewer); International Conference on Machine Learning (ICML); International Conference on Learning Representations (ICLR); Artificial Intelligence and Statistics (AISTATS).
期刊: Journal of Machine Learning Research (JMLR); Transactions on Pattern Analysis and Machine Intelligence (TPAMI); Pattern Recognition (PR); Transactions on Machine Learning Research (TMLR); Journal of Machine Learning (JML).
助教
深度学习理论, 由李志远 (TTIC) 教授讲授, 北京大学 (2023 年暑期学校).
高等数学, 北京大学 (从 2021 年秋季至 2024年 秋季).
近期新闻
[2026.04] 一篇论文被 ICML 2026 接收;一篇论文被 ACL 2026 接收。
[2026.01] 两篇论文被 ICLR 2026 接收,其中一篇被选为 Oral (前 1.2%)。
[2025.11] 我获得了 “字节跳动奖学金” (颁发给中国和新加坡共20名学生)。
[2025.09] 一篇论文被 NeurIPS 2025 接收,并选为 Spotlight (前 3.5%)。
[2025.05] 一篇文章被 ICML 2025 接收。
[2025.01] 一篇文章被 ICLR 2025 接收,并选为 Spotlight (前 5.1%)。
[2024.12] 我获得了 “国家自然科学基金青年学生基础研究项目(博士研究生)” 资助。
[2024.09] 我获得了 “国家奖学金 (博士)” (全国前 0.2%)。
[2024.09] 三篇论文被 NeurIPS 2024 接收。
[2024.05] 一篇论文被 ICML 2024 接收;一篇论文被 ACL 2024 接收。
[2023.11] 我获得了 “北大数学研究生奖” (前 1%)。
[2023.09] 一篇论文被 NeurIPS 2023 接收,并选为 Spotlight (前 3.5%)。
[2022.11] 我通过了博士生资格考试。
[2022.10] 我获得了 “北京大学学术创新奖” (前 1%)。
[2022.09] 两篇论文被 NeurIPS 2022 接收。
